In the upcoming five to seven years, many of the major research infrastructures will undergo an upgrade that results in at least an order of magniture more data, more collaborators, or more services. This holds across the board: from astronomy with the SKA Square Kilometre Array, earth observation with Copernicus, high-energy physics with the ‘HL-LHC’ High Luminosity Large Hadron Collider, the life sciences in Health-RI, neutrino telescopes with KM3NeT, and many more. Moreover, these services are increasingly interconnected, with the technological developments transferred and shared between domains. Data-intensive domains abound, and as data volumes increase due to higher resolution, more dense sensor networks, and sheer size of instrumented area or volume. And it expands beyond fundamental research as data acquisition and processing become the basis for policy making, for example in Earth Observation and sensing.
Meanwhile, data intensive research keeps pushing innovation, from Token based access and the data-lake technology for the high-luminosity LHC being foundational for the whole EOSC Science Cluster for Astronomy and Astro/Particle Physics (ESCAPE: https://projectescape.eu/) cluster (ESCAPE DIOS) - where challenges are shared between (Radio) Astronomy, Astroparticle physics, gravitational wave research, to the Life Sciences, and other data-intensive domains in the EOSC. Federated processing and analysis platforms - science gateways and other web-based research environments, such as the ESCAPE ESAP, data-intensive Jupyter Hubs with federated High Throughput Computing (HTC) and unified compute back-end systems and research data management for voluminous data - are being deployed across our globally distributed networks.
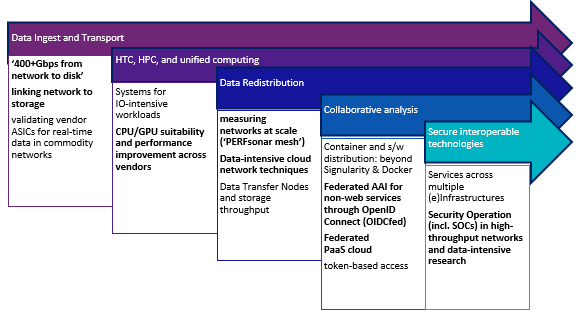
To meet these challenges, we must change both the e-Infrastructure itself as well as the way we connect with users and collaborate with our global peer facilities. Terabit-per-second data flows not only need to traverse the network, but also need to be stored, retrieved, processed, and shared globally. Processing algorithms must be optimized (e.g., AI-assisted/driven) and move to dedicated accelerated co-processors to keep up with the throughput, pushing GPU computing, Data Processing Units (DPUs), FPGAs and even combinations thereof.